33 KiB
| title | date | updated | tags | categories | keywords | description | top_img | comments | cover | toc | toc_number | toc_style_simple | copyright | copyright_author | copyright_author_href | copyright_url | copyright_info | katex | highlight_shrink | aside |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GraphGAN_ Graph Representation Learning_with Generative Adversarial Nets | 2020-12-17 21:04:43 | 2022-01-03 14:07:07 | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | <nil> | true | <nil> | <nil> |
GraphGAN:基于生成对抗性网络的图表示学习
摘要:
图表示学习的目标是将图中的每个顶点嵌入到低维的向量空间中。现有的图表示学习方法可以分为两类:学习图中潜在连通性分布的生成性模型和预测顶点对之间存在边的概率的判别性模型。在本文中,我们提出了一种创新的图表示学习框架GraphGAN,它结合了上述两类方法,其中生成模型和判别模型玩的是博弈论的极大极小博弈。具体地说,对于给定的顶点,生成模型试图在所有其他顶点上拟合其潜在的真实连通性分布,并产生“假”样本来欺骗判别模型,而判别模型则试图检测采样的顶点是来自地面真实还是由生成模型生成。随着这两种模式的竞争,它们都可以交替迭代地提升自己的性能。此外,在考虑产生式模型的实现时,我们提出了一种新的图Softmax,克服了传统Softmax函数的局限性,能够满足归一化、图结构感知和计算效率等方面的要求。通过在真实数据集上的广泛实验,我们证明了GraphGAN在链接预测、节点分类和推荐等各种应用上都比最先进的基线有了很大的提高。
Introduction
图表示学习(Graph representation learning),又称网络嵌入(network embedding),其目的是将图(network)中的每个顶点以低维向量的形式表示出来,便于对顶点和边进行网络分析和预测。学习的嵌入能够使广泛的现实世界应用受益,例如链接预测(Gao、Denoyer和Gallinari 2011)、节点分类(Don、Aggarwal和Liu 2016)、推荐(Yu等人。2014)、可视化(Maten和Hinton 2008)、知识图表示(Lin等人。2015)、集群(Tian et al.。2014)、文本嵌入(唐、曲和梅2015)和社交网络分析(Liu等人。2016)。最近,研究人员发现。考察了将表示学习方法应用于各种类型的图,例如加权图(Grover和Leskovec 2016)、有向图(周等人)。2017),签名图(Wang等人。2007b)、异构图(Wang等人。2018)和属性图(黄、李和胡2017)。此外,一些先前的工作也试图在学习过程中保留特定的属性,例如全局结构(Wang,Cui和朱2016),社区结构(Wang等人。2017c)、群信息(Chen,Zhang和Huang 2016)以及非对称及物性(ou等人。2016)。
可以说,大多数现有的图形表示学习方法可以分为两类。第一种是生成性图形表示学习模型(Perozzi,Al-Rfou和Skiena,2014;Grover和Leskovec,2016;周等人)。2017年;董、舒拉和斯瓦米2017;李等人。(2017a)。类似于经典的生成模型,例如高斯混合模型(Lindsay 1995)或潜在狄利克雷分配(Blei,Ng,and Jordan 2003),生成图表示学习模型假定,对于每个顶点VC,存在潜在的真实连通性分布ptrue(v|vc),这意味着VC相对于图中所有其他顶点的连通性偏好(或相关性分布)。因此,图中的边可以看作由这些条件分布生成的观察样本,并且这些生成模型通过最大化图中边的可能性来学习顶点嵌入。 例如,DeepWalk(Perozzi,Al-Rfou和Skiena 2014)使用随机游走对每个顶点的“上下文”顶点进行采样,并尝试最大化给定顶点的上下文顶点观测的对数似然率。Node2vec(Grover和Leskovec 2016)通过提出有偏的随机行走过程进一步扩展了这一想法,该过程在为给定顶点生成上下文时提供了更大的灵活性。
第二种图形表示学习方法是判别模型(Wang et al.。2018;曹、鲁、徐,2016;王、崔、朱,2016;李等人。2017b)。与产生式模型不同的是,判别图表示学习模型不把边看作是从潜在的条件分布中产生的,而是直接学习用于预测边的存在的分类器。通常,判别模型将两个顶点vi和vj共同视为特征,并基于图中的训练数据预测这两个顶点之间存在边的概率,即p(edge|(vi,vj))。例如,SDNE(Wang,第三十二届AAAI人工智能大会(AAAI-18)第三十二届AAAI人工智能大会(AAAI-18)崔和朱2016)使用顶点的稀疏邻接向量作为每个顶点的原始特征,并应用自动编码器在边存在的监督下提取顶点的简短和浓缩特征。PPNE(Li et al.。2007b)通过对正样本(连通顶点对)和负样本(不连通顶点对)的监督学习直接学习顶点嵌入,在学习过程中还保留了顶点的固有属性。
虽然生成模型和判别模型通常是两类互不相交的图形表示学习方法,但它们可以被认为是一枚硬币的两面(Wang et al.。(2017a)。事实上,LINE(唐等人)。2015年)对这两个目标(一阶和二阶邻近度,也就是所谓的一阶邻近度和二阶邻近度)进行了隐式结合的初步试验。最近,生成性对抗性网络(GAN)(古德费罗等人)。2014年)受到了极大的关注。通过设计一个博弈论的极小极大博弈来结合生成性和鉴别性模型,GAN及其变体在各种应用中取得了成功,例如图像生成(Denton et al.。2015),序列生成(Yu等人。2017)、对话生成(Li等人。2007c),信息检索(Wang等人。2017a)和域名自适应(Zhang、Barzilay和Jaakkola 2017)。
受GAN的启发,本文提出了一种结合生成性思维和鉴别性思维的图形表示学习框架GraphGAN。具体地说,我们的目标是在GraphGAN的学习过程中训练两个模型:1)生成器G(v|vc),它试图尽可能地拟合底层的真实连通分布ptrue(v|vc),并生成最有可能与vc相连的顶点;2)判别器D(v,vc),它试图区分连通良好和不连通的顶点对,并计算v和vc之间是否存在边的概率。在所提出的GraphGAN中,生成器G和鉴别器D充当极小极大博弈中的两个参与者:生成器试图在鉴别器提供的指导下产生最难区分的“假”顶点,而鉴别器则试图在地面真实和“伪”之间划清界限,以避免被生成器愚弄。这个游戏中的竞争驱使它们都提高自己的能力,直到生成器与真正的连通性分布难以区分。
在GraphGAN框架下,研究了生成器和鉴别器的选择。不幸的是,我们发现传统的Softmax函数(及其变体)不适合生成器,原因有二:1)Softmax对给定的顶点对图中的所有其他顶点一视同仁,没有考虑图的结构和邻近性信息;2)Softmax的计算涉及图中的所有顶点,耗时长,计算效率低。为了克服这些局限性,在GraphGAN中,我们提出了一种新的生成器实现,称为Graph Softmax。Graph Softmax提供了图中连通性分布的新定义。我们证明了图Softmax满足归一化、图结构感知和计算效率的理想性质。因此,我们提出了一种基于随机游走的生成器在线生成策略,该策略与图Softmax的定义一致,可以大大降低计算复杂度。
根据经验,我们使用五个真实世界的图结构数据集,将GraphGAN应用于三个真实世界的场景,即链接预测、节点分类和推荐。实验结果表明,与目前最先进的基线相比,GraphGAN在图表示学习领域取得了显著的进步。具体来说,GraphGAN在链路预测和节点分类上的准确率分别比基线高出0.59%到11.13%和0.95%到21.71%。此外,GraphGAN在推荐方面将Precision@20至少提高了38.56%,将Recall@20至少提高了52.33%。我们将GraphGAN的优势归因于其统一的对抗学习框架,以及邻近感知图softmax的设计,该设计可以自然地从图中捕捉结构信息。
图生成对抗网络
在本节中,我们将介绍GraphGAN的架构,并讨论生成器和鉴别器的实现和优化的细节。在此基础上,给出了作为生成函数实现的图softmax,并证明了其优于传统softmax函数的性质。
GraphGAN框架
我们制定了用于图表示学习的生成对抗网络,如下所示。令G =(V,E)为给定图,其中V = {v1,...,vV}表示一组顶点,而E = {eij} V i,j = 1表示一组边。对于给定的顶点vc,我们将N(vc)定义为直接连接到vc的一组顶点,其大小通常远小于顶点V的总数。我们将顶点vc的基础真实连通性分布表示为条件概率ptrue(v | vc),它反映了vc在V中所有其他顶点上的连通性偏好分布。从这个角度来看,N(vc)可以看作是一组从ptrue(v | vc)提取的观察样本。给定图G,我们旨在学习以下两个模型:
生成器G(v | vc;θG)尝试近似基本的真实连通性分布ptrue(v | vc),并从顶点集V生成(或选择,如果更精确的话)与vc连接的最可能的顶点。
鉴别符D(v,vc;θD),目的是鉴别顶点对(v,vc)的连通性。 D(v,vc;θD)输出单个标量,表示在v和vc之间存在边的概率。
生成器G和鉴别器D充当两个对手:生成器G试图完美地拟合ptrue(v|vc),并生成与vc的真实近邻相似的相关顶点来欺骗鉴别器,而鉴别器D则试图检测这些顶点是vc的真实近邻还是由其对应的G生成的顶点。形式上,G和D正在用值函数V(G,D)玩下面的两人极小极大博弈:
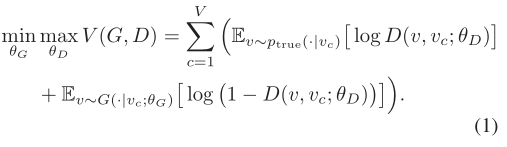
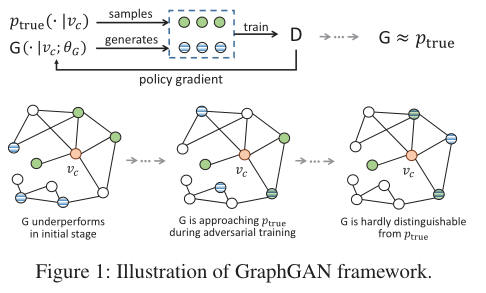 基于等式(1),通过交替地最大化和最小化值函数V(G,D)可以学习生成器和鉴别器的最佳参数。 GraphGAN框架如图1所示。在每次迭代中,使用来自ptrue(·| vc)的正样本(绿色的顶点)和来自生成器G(·| vc;θG)的负样本(具有蓝色条纹),然后在D的指导下使用策略梯度更新生成器G(本节稍后详细介绍)。 G和D之间的竞争驱使他们俩都改进自己的方法,直到G与真正的连接分布无法区分。我们讨论D和G的实现和优化如下。
基于等式(1),通过交替地最大化和最小化值函数V(G,D)可以学习生成器和鉴别器的最佳参数。 GraphGAN框架如图1所示。在每次迭代中,使用来自ptrue(·| vc)的正样本(绿色的顶点)和来自生成器G(·| vc;θG)的负样本(具有蓝色条纹),然后在D的指导下使用策略梯度更新生成器G(本节稍后详细介绍)。 G和D之间的竞争驱使他们俩都改进自己的方法,直到G与真正的连接分布无法区分。我们讨论D和G的实现和优化如下。
判别器优化
给定来自真实连通性分布的正样本和来自生成器的负样本,判别器的目标是最大化为正样本和负样本分配正确标签的对数概率,如果D是可微的,则可以通过随机梯度上升来解决关于θD。在GraphGAN中,我们将D定义为两个输入顶点的内积的S形函数:
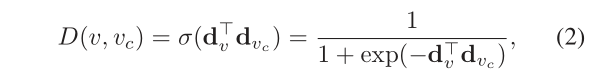 式中dv, dvc∈Rk分别是顶点v和vc对鉴别器D的k维表示向量,θD是所有dv的并集。任何判别模型在这里都可以作为D,如SDNE (Wang, Cui, and Zhu 2016),关于判别器选择的进一步研究留到以后的工作中。注意,Eq.(2)只涉及到v和vc,这表明给定一个样本对(v, vc),我们只需要通过对dv和dvc的梯度递增来更新它们:
式中dv, dvc∈Rk分别是顶点v和vc对鉴别器D的k维表示向量,θD是所有dv的并集。任何判别模型在这里都可以作为D,如SDNE (Wang, Cui, and Zhu 2016),关于判别器选择的进一步研究留到以后的工作中。注意,Eq.(2)只涉及到v和vc,这表明给定一个样本对(v, vc),我们只需要通过对dv和dvc的梯度递增来更新它们:
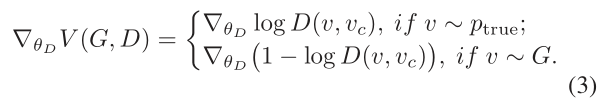
生成器优化
与鉴别器相比,生成器的目标是最小化鉴别器正确地将负标签分配给G生成的样本的对数概率。换句话说,生成器移动其近似连通性分布(通过其参数θG)以增加其生成的样本的分数,如D所判断的那样。因为v的采样是离散的,如下(Schulman等人)所述(Schulman et al.。2015年;Yu等人。2017),我们建议用策略梯度计算V(G,D)相对于θG的梯度:
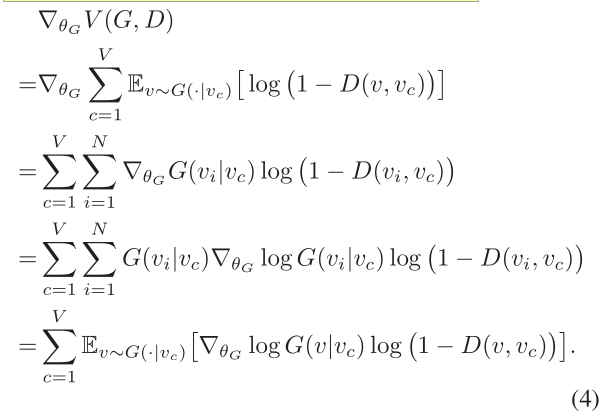 为了理解上述公式,值得注意的是,梯度∇θGV(G,D)是对数proθGlog G(v | vc;θG)的预期总和,并通过对数概率log 2(1−D(v, vc;θD)) , 从直觉上讲,它表明具有较高可能性成为负样本的顶点将使拖拽生成器G远离自身,因为我们对θG应用了梯度下降。
为了理解上述公式,值得注意的是,梯度∇θGV(G,D)是对数proθGlog G(v | vc;θG)的预期总和,并通过对数概率log 2(1−D(v, vc;θD)) , 从直觉上讲,它表明具有较高可能性成为负样本的顶点将使拖拽生成器G远离自身,因为我们对θG应用了梯度下降。
现在我们讨论G的实现。一种直接的方法是将生成器定义为所有其他顶点上的softmax函数(Wang等人2017a),即:
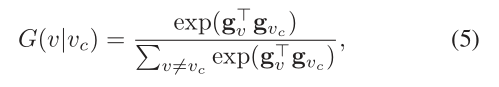 其中gv,gvc∈Rk分别是生成器G的顶点v和vc的k维表示向量,而θG是所有gv的并集。在此设置下,为了在每次迭代中更新θG,我们基于等式计算近似的连通性分布G(v | vc;θG)。 (5)根据G随机抽取一组样本(v,vc),并通过随机梯度下降更新θG。 Softmax为G中的连通性分布提供了简洁直观的定义,但在图形表示学习中有两个限制:1)在等式中计算softmax。 (5)涉及图中的所有顶点,这意味着对于每个生成的样本v,我们需要计算梯度∇θGlog G(v | vc;θG)并更新所有顶点。这在计算上效率低下,尤其是对于具有数百万个顶点的现实世界大型图。 2)图结构编码了顶点之间的丰富信息,但是softmax完全无视来自图的结构信息,因为它不加区别地对待顶点。最近,分层softmax(Morin和Bengio 2005)和负采样(Mikolov等人,2013)是softmax的流行替代方案。尽管这些方法可以在某种程度上减轻计算的负担,但是它们都没有考虑图形的结构信息,因此在应用于图形表示学习时无法获得令人满意的性能。
其中gv,gvc∈Rk分别是生成器G的顶点v和vc的k维表示向量,而θG是所有gv的并集。在此设置下,为了在每次迭代中更新θG,我们基于等式计算近似的连通性分布G(v | vc;θG)。 (5)根据G随机抽取一组样本(v,vc),并通过随机梯度下降更新θG。 Softmax为G中的连通性分布提供了简洁直观的定义,但在图形表示学习中有两个限制:1)在等式中计算softmax。 (5)涉及图中的所有顶点,这意味着对于每个生成的样本v,我们需要计算梯度∇θGlog G(v | vc;θG)并更新所有顶点。这在计算上效率低下,尤其是对于具有数百万个顶点的现实世界大型图。 2)图结构编码了顶点之间的丰富信息,但是softmax完全无视来自图的结构信息,因为它不加区别地对待顶点。最近,分层softmax(Morin和Bengio 2005)和负采样(Mikolov等人,2013)是softmax的流行替代方案。尽管这些方法可以在某种程度上减轻计算的负担,但是它们都没有考虑图形的结构信息,因此在应用于图形表示学习时无法获得令人满意的性能。
生成器的图softmax
为了解决上述问题,在GraphGAN中,我们提出了一种用于生成器的新的Softmax替代方案,称为图Softmax。图Softmax的核心思想是定义一种计算生成器G(·|vc;θG)中连通性分布的新方法,该方法满足以下三个期望性质: ·正常化。生成器应该产生一个有效的概率分布,即<EFBFBD>v̸=vc G(v|vc;θG)=1。 ·图形结构感知。生成器应该利用图的结构信息来近似真实的连通性分布。直观地说,对于图中的两个顶点,它们的连通概率应该随着它们的最短距离的增加而下降。 ·计算效率高。与全软最大值不同,G(v|vc;θG)的计算应该只涉及图中的少量顶点。
我们将详细讨论图Softmax,如下所示。为了计算连通性分布G(·|vc;θG),我们首先从顶点vc开始对原始图G执行广度优先搜索,这为我们提供了一个以vc为根的广度优先树Tc。给定Tc,我们将NC(V)表示为Tc中v(即,与v直接相连的顶点)的邻域集合,包括它的父顶点和所有子顶点(如果存在)。对于给定的顶点v和它的一个邻点vi∈NC(V),我们定义给定v的vi的关联概率为:
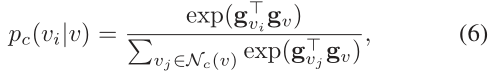 实际上是Nc(v)上的softmax函数。要计算G(v | vc;θG),请注意,可以从Tc中的根vc通过唯一路径到达每个顶点v。将路径表示为Pvc→v =(vr0,vr1,...,vrm),其中vr0 = vc和vrm = v。
然后,图softmax定义G(v | vc;θG)如下:
实际上是Nc(v)上的softmax函数。要计算G(v | vc;θG),请注意,可以从Tc中的根vc通过唯一路径到达每个顶点v。将路径表示为Pvc→v =(vr0,vr1,...,vrm),其中vr0 = vc和vrm = v。
然后,图softmax定义G(v | vc;θG)如下:
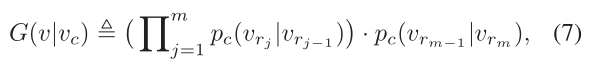 其中pc(·|·)是等式(6)中定义的相关概率 。
其中pc(·|·)是等式(6)中定义的相关概率 。
我们证明了我们提出的图softmax满足上述三个属性,即图softmax被规范化,图结构感知并且计算效率高。
 证明。在证明定理之前,我们首先给出如下命题。将STv表示为以Tc中的v为根的子树(v = vc)。那我们有
证明。在证明定理之前,我们首先给出如下命题。将STv表示为以Tc中的v为根的子树(v = vc)。那我们有
 其中(vr0,vr1,...,vrm)在路径Pvc→v上,vr0 = vc并且vrm = v。该命题可以通过BFS树Tc上的自底向上归纳来证明:
其中(vr0,vr1,...,vrm)在路径Pvc→v上,vr0 = vc并且vrm = v。该命题可以通过BFS树Tc上的自底向上归纳来证明:
 •对于每个非叶顶点v,我们将Cc(v)表示为Tc中v的子顶点集。通过归纳假设,每个子顶点vk∈Cc(v)满足等式(8)中的命题。
•对于每个非叶顶点v,我们将Cc(v)表示为Tc中v的子顶点集。通过归纳假设,每个子顶点vk∈Cc(v)满足等式(8)中的命题。
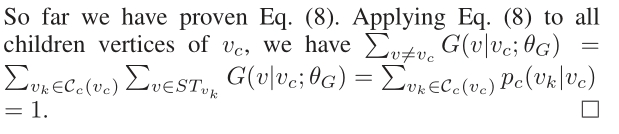
定理2。在图softmax中,G(v | vc;θG)随着原始图G中v和vc之间最短距离的增加而呈指数下降。 证明。根据图softmax的定义,G(v | vc;θG)是m + 1个相关概率项的乘积,其中m是路径Pvc→v的长度。请注意,m也是图G中vc和v之间的最短距离,因为BFS树Tc保留了vc和原始图中所有其他顶点之间的最短距离。因此,我们得出结论,G(v | vc;θG)与G中v和vc之间最短距离的倒数成指数比例。 根据定理2,我们通过在实验部分进行实证研究,进一步证明了图softmax精确地描述了连通性分布的真实模式。
**定理3.**在图softmax中,G(v | vc;θG)的计算取决于O(d log V)顶点,其中d是顶点的平均度,而V是图中G的顶点数。 证明。根据等式。 (6)和等式(7),G(v | vc;θG)的计算涉及两种类型的顶点:路径Pvc→v上的顶点和直接连接到路径的顶点(即距路径的距离为1的顶点)。通常,路径的最大长度为log V,即BFS树的深度,并且路径中的每个顶点平均连接到d个顶点。因此,G(v | vc;θG)中涉及的顶点总数为O(d log V)。
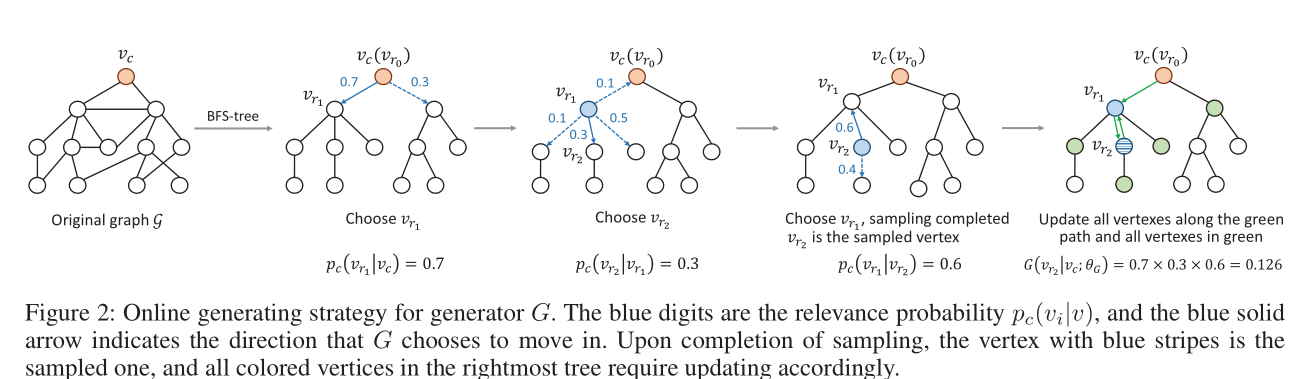
接下来,我们讨论生成器G的生成(或采样)策略。生成顶点的可行方法是计算所有顶点v̸= vc的G(v | vc;θG),并根据它们的近似连通性概率按比例执行随机采样。在这里,我们提出一种在线生成方法,该方法计算效率更高,并且与图softmax的定义一致。为了生成一个顶点, 我们相对于等式(6)中定义的转移概率从Tc中的根Vc开始执行随机行走。在随机游走过程中,如果当前访问的顶点是v,并且生成器G决定第一次访问v的父节点(即在路径上转身),则选择v作为生成的顶点。
算法1中正式描述了生成器的在线生成策略。我们将当前访问的顶点表示为vcur,将先前访问的顶点表示为vpre。请注意,算法1以O(log V)步终止,因为随机游走路径最迟在到达叶顶点时会转弯。类似于图softmax的计算,上述在线生成方法的复杂度为O(d log V),大大低于离线方法的复杂度为O(V·d log V)。图2给出了生成策略以及图softmax的计算过程的说明性示例。在随机游动的每个步骤中,通过与等式(eq)中定义的相关概率pc(vi | vcur)成比例的随机选择,从vcur的所有邻居中选择一个蓝色顶点vi。 (6)。一旦vi等于vpre,即随机游走重访了vcur的父vpre,将采样出vcur(图中图中带有蓝色条纹的顶点),并且沿路径Pvc→vcur的所有顶点以及直接连接到该路径的连接需要根据方程式进行更新。 (4),(6)和(7)。

 最后,在算法2中总结了GraphGAN的整体逻辑。我们提供了GraphGAN的时间复杂度分析,如下所示。第2行中所有顶点的BFS树构造的复杂度为O×V(V + E)= O(dV 2)。BFS的时间复杂度为O(V + E)(Cormen 2009)。
在每次迭代中,第5行和第6行的复杂度均为O(sV·d log V·k),第9行和第10行的复杂度为O(tV·d log V·k)和O(tV· k)。通常,如果将k,s,t和d视为常量,则GraphGAN中每次迭代的复杂度为O(V log V)。
最后,在算法2中总结了GraphGAN的整体逻辑。我们提供了GraphGAN的时间复杂度分析,如下所示。第2行中所有顶点的BFS树构造的复杂度为O×V(V + E)= O(dV 2)。BFS的时间复杂度为O(V + E)(Cormen 2009)。
在每次迭代中,第5行和第6行的复杂度均为O(sV·d log V·k),第9行和第10行的复杂度为O(tV·d log V·k)和O(tV· k)。通常,如果将k,s,t和d视为常量,则GraphGAN中每次迭代的复杂度为O(V log V)。
Experiments
在本节中,我们评估GraphGAN1在一系列实际数据集上的性能。具体而言,我们选择三种应用场景进行实验,即链接预测,节点分类和推荐。
实验设置
我们在实验中利用了以下五个数据集: •arXiv-AstroPh2来自电子版arXiv,涵盖作者之间的科学合作以及提交给Astro Physics类别的论文。顶点表示作者,边缘表示共同作者关系。此图具有18,772个顶点和198,110个边。 •arXiv-GrQc3也来自arXiv,涵盖作者之间的科学合作,并提交了广义相对论和量子宇宙学类别的论文。 该图具有5,242个顶点和14,496个边。 •BlogCatalog4是BlogCatalog网站上列出的博客作者的社交关系网络。顶点标签表示通过博客作者提供的元数据推断出的博客作者兴趣。此图具有10,312个顶点,333,982条边和39个不同的标签。 •Wikipedia5是单词的共现网络,出现在Eglish Wikipedia转储的前109个字节中。 标签代表推断的词性(POS)标签。此图具有4,777个顶点,184,812条边和40个不同的标签。 •MovieLens-1M6是一个二分图,由MovieLens网站上的6,400个用户和3,706部电影组成,包含大约100万个评分(边缘)。
我们将建议的GraphGAN与以下四个用于图形表示学习的基线进行比较: •DeepWalk(Perozzi,Al-Rfou和Skiena 2014)采用随机游走和Skip-Gram学习顶点嵌入。 •LINE(Tang等人,2015)保留了图中顶点之间的一阶和二阶接近度。 •Node2vec(Grover和Leskovec,2016年)是DeepWalk的一种变体,设计了一种偏向随机游动来学习顶点嵌入。 •Struc2vec(Ribeiro,Saverese和Figueiredo 2017)捕获图形中顶点的结构标识。
对于所有三个实验方案,我们执行随机梯度下降以更新GraphGAN中的参数,学习速率为0.001。在每次迭代中,我们将s设置为20,将t设置为每个顶点在测试集中的正样本数,然后分别执行G步和D步30次。所有方法的表示向量k的维数设置为20。通过交叉验证选择上述超参数。最终学习到的顶点表示是gi。所有基线的参数设置均为默认设置。
实证研究
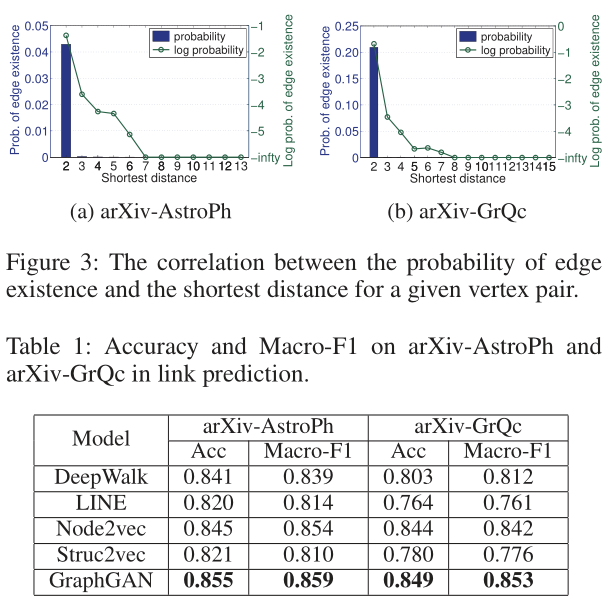
我们进行了一项实证研究,以研究图中连通性分布的实际模式。具体来说,对于给定的顶点对,我们旨在揭示边缘存在的概率如何随着图中最短距离的变化而变化。为此,我们首先分别从arXiv-AstroPh和arXiv-GrQc数据集中随机抽取了100万个顶点对。对于每个选定的顶点对,我们删除它们之间存在的边(如果存在)(因为它被视为隐藏的地面真相),并计算它们的最短距离。我们计算所有可能的最短距离上边缘存在的概率,并在图3中绘制结果(未连接的情况被省略)。显然,顶点对之间存在边的概率随着顶点对之间最短距离的增加而急剧下降。我们还绘制了图3中的对数概率曲线,该曲线通常趋向于线性下降,R2=0.831和0.710。上述发现从经验上证明了两个顶点之间存在边的概率近似指数地与它们的最短距离的倒数成正比,这有力地证明了根据定理2,图Softmax抓住了现实世界图的本质。
链路预测
在链接预测中,我们的目标是预测两个给定顶点之间是否存在边。因此,本课题展示了不同图表示学习方法的边可预测性性能。我们在原始图中随机隐藏10%的边作为基本事实,并用左图训练所有的图表示学习模型。训练后,我们得到所有顶点的表示向量,并使用Logistic回归方法预测给定顶点对的边存在概率。我们的测试集包括原始图中隐藏的10%的顶点对(边)作为正样本,随机选择的不连通的顶点对作为数量相等的负样本。我们使用arxiv-AstroPh和arxiv-GrQc作为数据集,并在表1中报告了精度和Macro-F1的结果。我们的观察结果如下:1)line和struc2vec在链接预测中的性能相对较差,因为它们不能很好地捕捉图中的边存在模式。2)DeepWalk和node2vec的性能优于line和struc2vec。这可能是因为DeepWalk和node2vec都使用了基于随机行走的Skip-Gram模型,该模型在提取顶点之间的邻近信息方面做得更好。3)GraphGAN在链接预测方面优于所有基线。具体地说,GraphGAN将arxiv-AstroPh和arxiv-GrQc的准确率分别提高了1.18%到4.27%和0.59%到11.13%。可以说,对抗性训练比传统的单一模型训练为GraphGAN提供了更高的学习灵活性。

 为了直观地了解GraphGAN的学习稳定性,我们在图4中进一步说明了生成器和判别器在arXiv-GrQc上的学习曲线。从图4中我们观察到GraphGAN中的minimax游戏达到了均衡,其中生成器表现出色。在收敛之后,鉴别器的性能首先增强,但逐渐降至0.8以下。
注意,鉴别器不会降级到随机猜测的水平,因为在实践中,生成器仍然提供许多真实的负样本。结果表明,与IRGAN不同(Wang等人,2017a),图softmax的设计使GraphGAN中的生成器可以绘制样本并更有效地学习顶点嵌入。
为了直观地了解GraphGAN的学习稳定性,我们在图4中进一步说明了生成器和判别器在arXiv-GrQc上的学习曲线。从图4中我们观察到GraphGAN中的minimax游戏达到了均衡,其中生成器表现出色。在收敛之后,鉴别器的性能首先增强,但逐渐降至0.8以下。
注意,鉴别器不会降级到随机猜测的水平,因为在实践中,生成器仍然提供许多真实的负样本。结果表明,与IRGAN不同(Wang等人,2017a),图softmax的设计使GraphGAN中的生成器可以绘制样本并更有效地学习顶点嵌入。
节点分类
在节点分类中,为每个顶点分配一个或多个标签。在观察一部分顶点及其标签后,我们旨在预测其余顶点的标签。因此,节点分类的性能可以揭示不同图表示学习方法下顶点的可区分性。为了进行实验,我们在整个图形上训练GraphGAN和基线以获得顶点表示,并使用逻辑回归作为分类器以9:1的训练测试比执行节点分类。我们使用BlogCatalog和Wikipedia作为数据集。表2列出了Accuracy和Macro-F1的结果。正如我们所看到的,GraphGAN在两个数据集上的表现均优于所有基线。例如,GraphGAN在两个数据集上的准确度分别提高了1.75%至13.17%和0.95%至21.71%。这表明,尽管GraphGAN是直接设计用于优化边缘上的近似连通性分布,它能有效地将顶点信息编码进学习的表示。
Recommendation
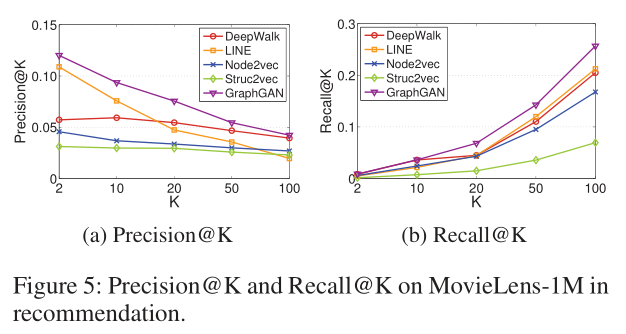
我们使用Movielens-1M作为推荐的数据集。对于每个用户,我们的目标是推荐一组没有看过但用户可能喜欢的电影。我们首先将所有的4星和5星评级作为边来处理,得到一个二部图,然后在原始图中随机隐藏10%的边作为测试集,并为每个用户构造一棵BFS-树。注意,与上面两个实验场景不同的是,在上面的两个实验场景中,针对特定顶点在所有其他顶点上定义连通性分布,在推荐中,一个用户的连通性概率仅分布在图中的一小部分顶点上,即,所有电影上。因此,我们通过在由用户顶点链接的所有电影对中添加直接边来对bfs-tree中的所有用户顶点(根除外)进行“捷径”。在训练并获得用户和电影的表示后,对于每个用户,我们选择K部内积最高的未看电影作为推荐结果。Precision@K和Recall@K的结果如图5所示,从中我们可以观察到,GraphGAN始终高于所有基线,并且在这两个指标上都实现了统计上的显著改进。以Precision@20为例,GraphGan的性能分别比DeepWalk、Line、node2vec和struc2vec高出38.56%、59.60%、124.95和156.85。因此,我们可以得出结论,与其他图表示学习方法相比,GraphGAN在基于排序的任务中保持了更好的性能。
Conclusions
在本文中,我们提出了GraphGAN,它通过在极小极大博弈中的对抗性训练,统一了图表示学习方法的两个流派,即生成法和判别法。在GraphGAN框架下,生成器和鉴别器都可以从彼此中受益:生成器由鉴别器的信号引导并提高其生成性能,而鉴别器由生成器推动以更好地区分地面真实和生成的样本。 此外,我们还提出了图Softmax作为生成器的实现,解决了传统Softmax算法固有的局限性。我们在三种场景下对五个真实世界的数据集进行了实验,结果证明由于GraphGAN的对抗性框架和邻近感知图Softmax,GraphGAN在所有实验中的表现都明显优于强基线。
References
Blei, D. M.; Ng, A. Y.; and Jordan, M. I. 2003. Latent dirichlet allocation. Journal of machine Learning research 3(Jan):993– 1022. Cao, S.; Lu, W.; and Xu, Q. 2016. Deep neural networks for learning graph representations. In AAAI, 1145–1152. Chen, J.; Zhang, Q.; and Huang, X. 2016. Incorporate group information to enhance network embedding. In CIKM, 1901– 1904. ACM. Cormen, T. H. 2009. Introduction to algorithms. MIT press. Denton, E. L.; Chintala, S.; Fergus, R.; et al. 2015. Deep gen- erative image models using a laplacian pyramid of adversarial networks. In NIPS, 1486–1494. Dong, Y.; Chawla, N. V.; and Swami, A. 2017. metapath2vec: Scalable representation learning for heterogeneous networks. In KDD, 135–144. ACM. Gao, S.; Denoyer, L.; and Gallinari, P. 2011. Temporal link prediction by integrating content and structure information. In CIKM, 1169–1174. ACM. Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde- Farley, D.; Ozair, S.; Courville, A.; and Bengio, Y. 2014. Gen- erative adversarial nets. In NIPS, 2672–2680. Grover, A., and Leskovec, J. 2016. node2vec: Scalable feature learning for networks. In KDD, 855–864. ACM. Huang, X.; Li, J.; and Hu, X. 2017. Label informed attributed network embedding. In WSDM, 731–739. ACM. Li, C.; Li, Z.; Wang, S.; Yang, Y.; Zhang, X.; and Zhou, J. 2017a. Semi-supervised network embedding. In International Confer- ence on Database Systems for Advanced Applications, 131–147. Springer. Li, C.; Wang, S.; Yang, D.; Li, Z.; Yang, Y.; Zhang, X.; and Zhou, J. 2017b. Ppne: Property preserving network embedding. In International Conference on Database Systems for Advanced Applications, 163–179. Springer. Li, J.; Monroe, W.; Shi, T.; Ritter, A.; and Jurafsky, D. 2017c. Adversarial learning for neural dialogue generation. arXiv preprint arXiv:1701.06547. Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; and Zhu, X. 2015. Learning entity and relation embeddings for knowledge graph comple- tion. In AAAI, 2181–2187. Lindsay, B. G. 1995. Mixture models: theory, geometry and applications. In NSF-CBMS regional conference series in prob- ability and statistics, i–163. JSTOR. Liu, L.; Cheung, W. K.; Li, X.; and Liao, L. 2016. Aligning users across social networks using network embedding. In IJ- CAI, 1774–1780. Maaten, L. v. d., and Hinton, G. 2008. Visualizing data using t- sne. Journal of Machine Learning Research 9(Nov):2579–2605. Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G. S.; and Dean, J. 2013. Distributed representations of words and phrases and their compositionality. In NIPS, 3111–3119. Morin, F., and Bengio, Y. 2005. Hierarchical probabilistic neural network language model. In Aistats, volume 5, 246–252. Ou, M.; Cui, P.; Pei, J.; Zhang, Z.; and Zhu, W. 2016. Asym- metric transitivity preserving graph embedding. In KDD, 1105– 1114. Perozzi, B.; Al-Rfou, R.; and Skiena, S. 2014. Deepwalk: On- line learning of social representations. In KDD, 701–710. ACM. Ribeiro, L. F.; Saverese, P. H.; and Figueiredo, D. R. 2017. struc2vec: Learning node representations from structural iden- tity. In KDD, 385–394. ACM. Schulman, J.; Heess, N.; Weber, T.; and Abbeel, P. 2015. Gra- dient estimation using stochastic computation graphs. In NIPS, 3528–3536. Tang, J.; Aggarwal, C.; and Liu, H. 2016. Node classification in signed social networks. In Proceedings of the 2016 SIAM International Conference on Data Mining, 54–62. SIAM. Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; and Mei, Q. 2015. Line: Large-scale information network embedding. In WWW, 1067–1077. International World Wide Web Conferences Steering Committee. Tang, J.; Qu, M.; and Mei, Q. 2015. Pte: Predictive text embed- ding through large-scale heterogeneous text networks. In KDD, 1165–1174. ACM. Tian, F.; Gao, B.; Cui, Q.; Chen, E.; and Liu, T.-Y. 2014. Learn- ing deep representations for graph clustering. In AAAI, 1293– 1299. Wang, J.; Yu, L.; Zhang, W.; Gong, Y.; Xu, Y.; Wang, B.; Zhang, P.; and Zhang, D. 2017a. Irgan: A minimax game for unifying generative and discriminative information retrieval models. In SIGIR. ACM. Wang, S.; Tang, J.; Aggarwal, C.; Chang, Y.; and Liu, H. 2017b. Signed network embedding in social media. In Proceedings of the 2017 SIAM International Conference on Data Mining, 327– 335. SIAM. Wang, X.; Cui, P.; Wang, J.; Pei, J.; Zhu, W.; and Yang, S. 2017c. Community preserving network embedding. In AAAI, 203–209. Wang, H.; Zhang, F.; Hou, M.; Xie, X.; Guo, M.; and Liu, Q. 2018. Shine: Signed heterogeneous information network em- bedding for sentiment link prediction. In WSDM. ACM. Wang, D.; Cui, P.; and Zhu, W. 2016. Structural deep network embedding. In KDD, 1225–1234. ACM. Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; and Han, J. 2014. Personalized entity recom- mendation: A heterogeneous information network approach. In WSDM, 283–292. ACM. Yu, L.; Zhang, W.; Wang, J.; and Yu, Y. 2017. Seqgan: Sequence generative adversarial nets with policy gradient. In AAAI, 2852– 2858. Zhang, Y.; Barzilay, R.; and Jaakkola, T. 2017. Aspect- augmented adversarial networks for domain adaptation. arXiv preprint arXiv:1701.00188. Zhou, C.; Liu, Y.; Liu, X.; Liu, Z.; and Gao, J. 2017. Scalable graph embedding for asymmetric proximity. In AAAI, 2942– 2948.